Sissejuhatus Masinõppesse
Õpieesmärgid
Selle õppetunni lõpuks oskate:
- Defineerida masinõpet ja eristada seda traditsioonilisest programmeerimisest.
- Tuvastada masinõppe rakendusi reaalses elus.
- Eristada kolme peamist masinõppe tüüpi: juhendatud, juhendamata ja stiimulõpe.
Mis on Masinõpe?
Masinõpe (Machine Learning ehk ML) on tehisintellekti valdkond, kus arvutisüsteemid õpivad andmetest, et tuvastada mustreid ja teha otsuseid minimaalse inimese sekkumisega.
Kuigi tänapäeva tehisintellekti edusammud põhinevad suuresti just masinõppel, eriti selle alamvaldkonnal sügavõppel (deep learning), ei ole kogu tehisintellekt pelgalt masinõppe põhine. Masinõpe on vaid üks tehisintellekti "tööriistadest" või meetoditest, mitte kogu valdkond.
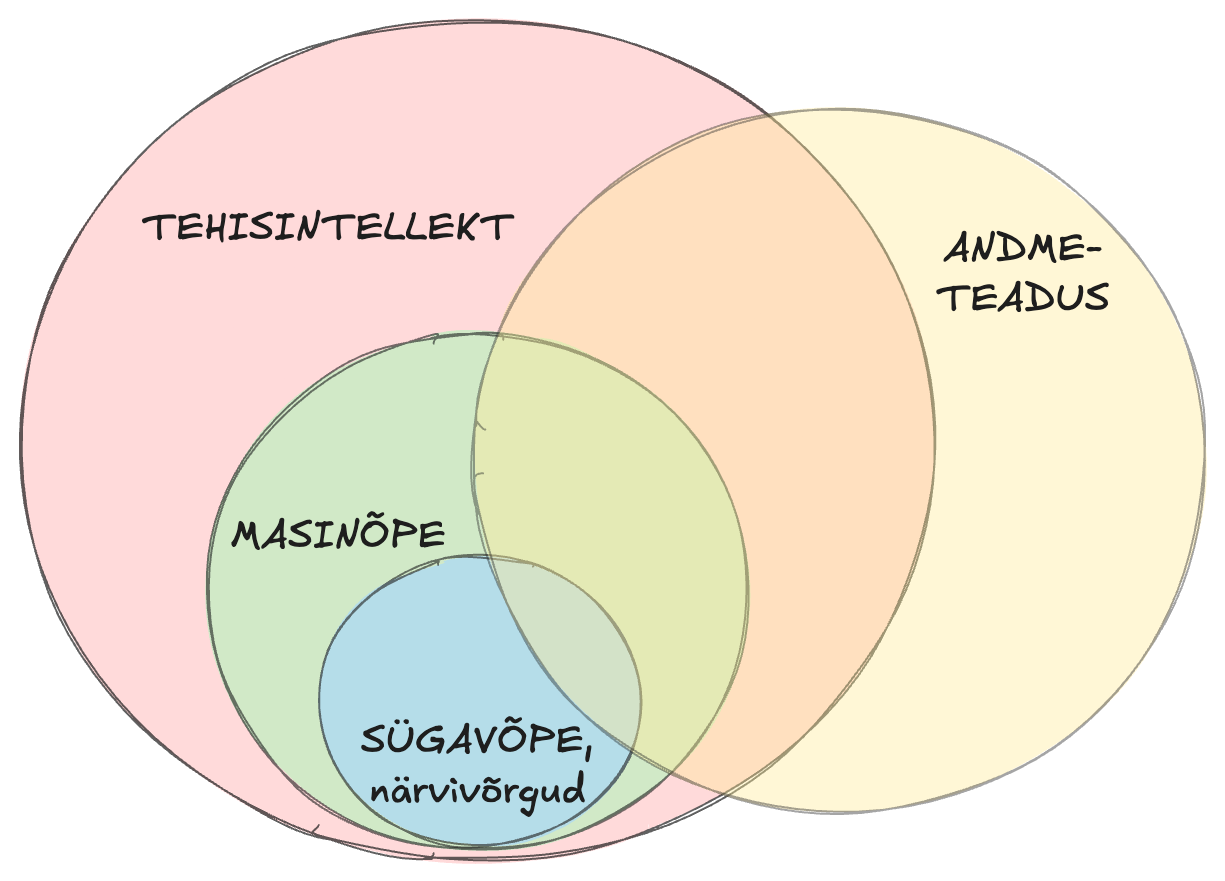
- Tehisintellekt (TI) on ülemine tase. See on üldine eesmärk - luua masinaid, mis suudavad mõelda ja toimida nagu inimesed.
- Masinõpe (ML) on üks viis, kuidas tehisintellekti saavutada. See on tehnika, mis võimaldab masinatel andmetest õppida.
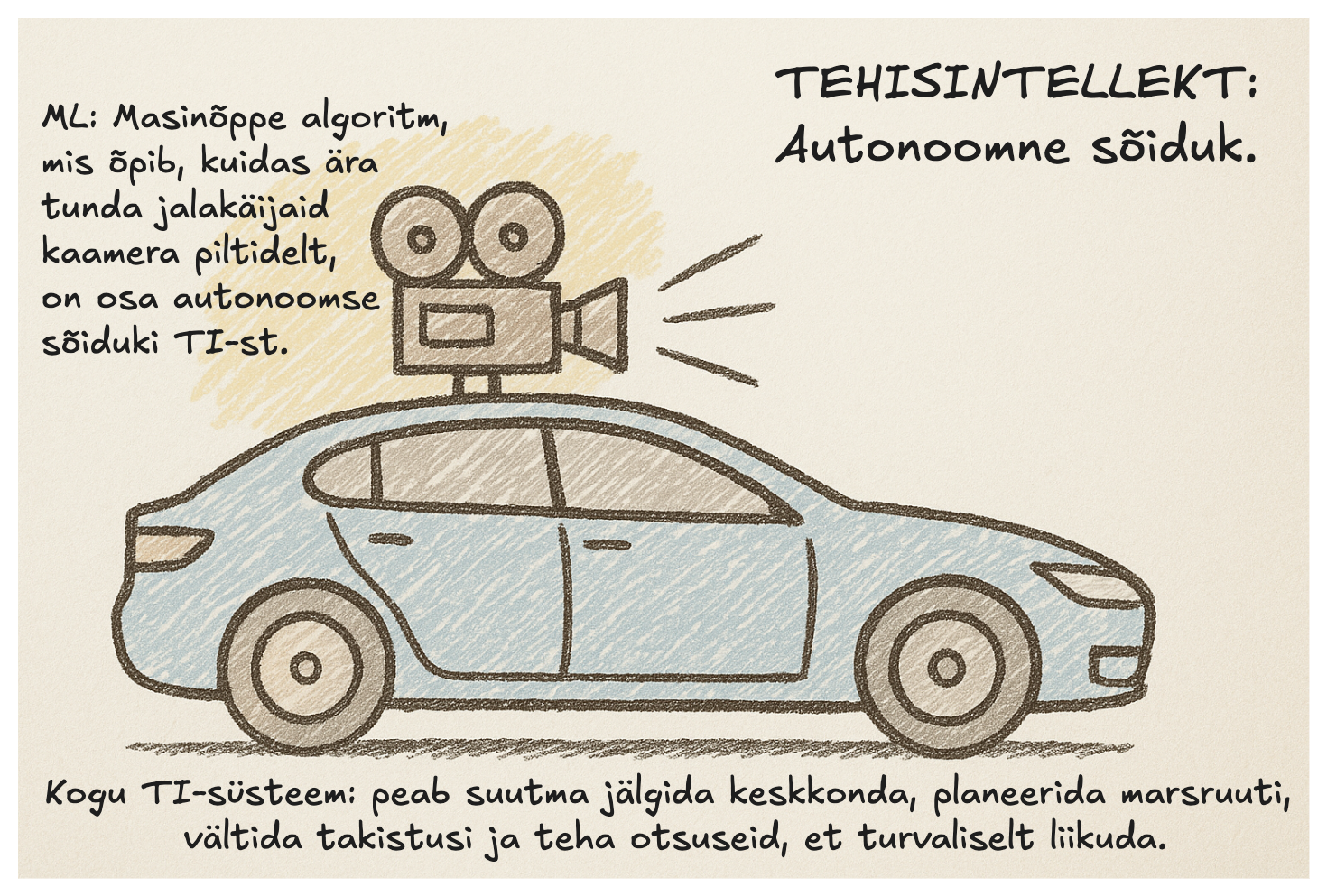
Erinevalt traditsioonilisest programmeerimisest, kus arendaja kirjutab iga ülesande jaoks selged reeglid, õpib masinõppe mudel reeglid ise, kui talle antakse piisavalt andmeid. See võimaldab lahendada keerulisi probleeme, kus reeglite käsitsi kirjeldamine oleks äärmiselt keerukas või võimatu.
Näiteks, kui mudel õpib piltidelt kasse ära tundma, suudab ta tuvastada kassi ka fotol, mida ta pole varem näinud.
Masinõpe vs Traditsiooniline programmeerimine
Traditsiooniline programmeerimine:
- Inimene kirjutab samm-sammulised juhised (algoritmi), mis määravad, kuidas sisendandmetest saadakse väljund.
- Hea valik probleemidele, kus reeglid on lihtsad, selged ja muutumatud.
- Näide: Kui soovime kontrollida, kas arv on positiivne, saame kirjutada konkreetse tingimuse (
if (number >= 0)).
Masinõpe:
- Inimene ei kirjuta reegleid, vaid annab näited (sisendid + õiged vastused) ja laseb arvutil need reeglid andmetest ise tuletada.
- Sobib probleemidele, kus reeglite leidmine käsitsi on keeruline või kus olukorrad muutuvad pidevalt.
- Näide: Näotuvastus. On peaaegu võimatu kirjutada käsitsi kõiki reegleid, kuidas ära tunda erinevate nurkade ja valgustingimustega nägu.
Lühidalt:
- Traditsiooniline programmeerimine: Andmed + Reeglid → Väljund
- Masinõpe: Andmed + Väljundid → Reeglid (Mudel)


Masinõppe töövoog
Masinõppe projekti töövoos järgitakse tavaliselt järgmisi samme:
-
Probleemi määratlemine: Töövoog algab selge probleemi sõnastamisega. Tuleb määratleda täpselt, mida soovitakse saavutada, otsustada, kas masinõpe on õige lahendus ning valida sobiv masinõppe tüüp (juhendatud, juhendamata või stiimulõpe). Seejärel saab defineerida edukuse mõõdikud nagu täpsus, tundlikkus või muud asjakohased näitajad.
-
Andmete kogumine ja salvestamine: Kogutakse asjakohased andmed erinevatest allikatest ning need salvestatakse sobivasse vormingusse edasiseks töötlemiseks. Kontrollitakse, et andmed oleksid probleemi lahendamiseks piisavad ja asjakohased.
-
Andmete eeltöötlus: Kogutud andmed puhastatakse, eemaldatakse duplikaadid, täidetakse puuduvad väärtused ning vormindatakse kõik ühtsele kujule selliselt, et iga muudatus jääb algse jaotuse ja üldise kuju piiresse, ega moonuta algses andmestikus peituvat olemust. Lõpuks jagatakse andmestik treenimis-, valideerimis- ja testandmeteks, tavaliselt vastavalt 70%, 15% ja 15% proportsioonides.
-
Mudeli valimine ja treenimine (õpetamine): Sõltuvalt ülesande tüübist ja andmete omadustest valitakse probleemi lahendamiseks sobiv algoritm (näiteks otsustuspuud, närvivõrgud või regressioon), mida treenitakse ettevalmistatud andmetel. Treenimise käigus õpib mudel tuvastama andmetes mustreid ja seoseid. Protsessi jälgitakse hoolikalt, et vältida üle- või alatreenitust ning vajadusel kohandatakse mudeli parameetreid parima tulemuse saavutamiseks.
-
Mudeli hindamine ja optimeerimine: Mudelit kontrollitakse eraldi valideerimisandmetega, et hinnata selle täpsust ja üldistusvõimet. Analüüsitakse tekkinud vigu ja tuvastatakse probleemsed kohad. Vajadusel kohandatakse parameetreid, algoritmi või andmeid.
-
Lõplik testimine: Parimat mudelit hinnatakse testandmetel. Kontrollitakse, et mudel töötaks hästi ka uutel, varem nägemata andmetel, mis tagab mudeli üldistusvõime. Arvutatakse erinevad mõõdikud nagu täpsus (kui suur osa ennustustest on õiged), keskmine ruutviga (kui suur on erinevus tegeliku ja ennustatud väärtuse vahel) või tundlikkus (kui hästi leitakse üles otsitavad juhtumid).
-
Mudeli elluviimine: Lõpuks viimistletakse mudelit, vajadusel korratakse eelmisi samme ja viiakse see tootmiskeskkonda, kus ta saab teha ennustusi uute andmete põhjal. See võib tähendada mudeli integreerimist veebilehte, mobiilirakendusse või muusse süsteemi.
-
Jälgimine ja hooldus: Pärast juurutamist tuleb mudeli jõudlust pidevalt jälgida ning vajadusel uuesti treenida uute andmetega. Maailm muutub pidevalt ja mudel peab sellega sammu pidama, et säilitada oma täpsust.
Töövoog ei ole alati lineaarne – tihti tuleb varasemate etappide juurde tagasi minna, et andmeid täiustada või mudelit kohandada.


Praktilised rakendused
Masinõpet kasutatakse paljudes rakendustes, mis loovad väärtust meie igapäevaellu. Mõned levinud näited on järgmised:
-
Isesõitvad autod: ML-mudelid töötlevad andureid (kaamerad, radar, lidar), et tuvastada objekte, ennustada nende liikumist ja teha navigeerimisotsuseid.
-
Rämpsposti filtrid: E-posti teenused kasutavad masinõpet sissetulevate sõnumite analüüsimiseks ja nende klassifitseerimiseks õigeks või rämpspostiks, tuginedes miljonitest e-kirjadest õpitud mustritele.
-
Soovitussüsteemid: Platvormid nagu Netflix ja Amazon kasutavad masinõppe algoritme, et analüüsida teie varasemat käitumist (vaadatud filme, ostetud tooteid) ja soovitada uusi tooteid, mis võiksid teile meeldida.
-
Ilmaprognoos: Masinõpe aitab analüüsida tohutuid andmemahte (temperatuur, niiskus, tuulekiirus) täpsemate ilmaprognooside tegemiseks, õppides varasemate ilmastikutingimuste mustreid.
-
Pettuste tuvastamine: Pangad ja finantsasutused kasutavad masinõpet kahtlaste tehingute tuvastamiseks, analüüsides kasutaja tavapärast käitumist ja märgates kõrvalekaldeid reaalajas.
-
Keeletõlge: Tõlkerakendused, nagu Google Translate, kasutavad masinõpet keelte vahel tõlkimiseks, parandades täpsust läbi suurte tekstikogumite analüüsi ja õppimise.
-
Toodete kvaliteedi kontroll: Tööstuses kasutatakse masinõppe põhiseid süsteeme, et automaatselt tuvastada defekte toodete tootmisprotsessis, analüüsides pilte ja andmeid.
-
Sisu modereerimine: Platvormid, nagu YouTube ja Twitter (X), kasutavad masinõpet sobimatu sisu (nt vihakõne, vägivald) tuvastamiseks ja eemaldamiseks, õppides kasutajate aruannetest ja reeglitest.
-
Energiatarbimise optimeerimine: Nutikad energiasüsteemid kasutavad masinõpet tarbimismustrite analüüsimiseks ja energiajaotuse optimeerimiseks, vähendades kulusid ja jäätmeid.
Märgistatud ja märgistamata andmed
Enne kui räägime märgistatud ja märgistamata andmetest, tasub selgelt mõista, mis on andmed. Lihtsustatult on andmed teave. Kui meil on tabel teabega, siis iga rida tabelis on andmepunkt. Näiteks kui meil on andmekogum lemmikloomadest, siis iga rida kirjeldab üht lemmiklooma. Lemmiklooma iseloomustavad tunnused — need on omadused või karakteristikud, mis kirjeldavad andmeid. Tabeli kontekstis on tunnused veerud: näiteks looma suurus, nimi, liik või kaal.
Mõned tunnused on eriliselt olulised ja neid nimetatakse siltideks. Silt on tunnus, mida me püüame teiste tunnuste põhjal ennustada. Näiteks kui soovime lemmiklooma omaduste põhjal ennustada, kas tegu on kassi või koeraga, siis silt on looma liik (kass/koer). Kui soovime ennustada, kas loom on haige või terve, siis silt on looma tervislik seisund. Kui eesmärk on ennustada looma vanust, siis silt on vanus (arvuline väärtus). Masinõppe mudeli eesmärk on nende siltide ennustamine — mudeli tehtud oletust nimetatakse prognoosiks.
Selle põhjal eristame kahte põhitüüpi andmeid:
- Märgistatud andmed – igal andmepunktil on nii tunnused kui ka sildid. Näiteks meil on e-kirjade andmekogum, kus on veerg, mis näitab, kas kiri on rämpspost või mitte.
- Märgistamata andmed – andmetel on ainult tunnused, kuid puudub silt, mida ennustada. Näiteks meil on e-kirjade andmekogum ilma veeruta, mis ütleks, kas kiri on rämpspost või mitte.


Masinõppe tüübid
Masinõppes on kolm peamist kategooriat, mis sobivad erinevat tüüpi probleemide lahendamiseks. Järgmistes peatükkides käsitleme neid tüüpe põhjalikumalt, kuid praegu on oluline teada nende nimesid ja põhimõisteid:
- Juhendatud õpe: selle tüüpi õpe hõlmab mudeli koolitamist märgistatud andmekogumil, kus iga andmeühik on märgistatud õige vastusega. Mudel õpib seostama sisendit väljundiga.
- Juhendamata õpe: selles lähenemisviisis antakse mudelile märgistamata andmed ja mudel peab ise leidma neis mustrid või struktuurid.
- Stiimulõpe: see on õppimise liik, kus agent õpib otsuseid tegema, suheldes keskkonnaga ja saades tagasisidet preemiate või karistuste vormis.
Piirangud ja eetika
Vaatamata oma võimsusele ei ole masinõpe ilma väljakutseteta. Oluline on arvestada järgmist:
- Eelarvamus: kui mudeli õppimiseks kasutatavad andmed on eelarvamuslikud, õpib mudel seda eelarvamust ja kinnistab selle, mis viib ebaõiglastele või ebatäpsetele tulemustele.
- Andmete kvaliteet: „Rämps sisse, rämps välja.” ML-mudeli jõudlus sõltub suuresti õppimisandmete kvaliteedist ja puhtusest.
- Privaatsus: masinõpe tugineb sageli suurtele andmehulkadele, mis tekitab märkimisväärseid probleeme seoses kasutajate privaatsuse ja andmete turvalisusega, kuid on ka meetodeid, mis töötavad väiksemate andmehulkadega, eriti kui kasutatakse eelõpetatud mudeleid.
Harjutus: Traditsiooniline programmeerimine või masinõpe
Kokkuvõte
Käesoleva materjaliga said selgeks masinõppe põhimõisted ja selle erinevus traditsioonilisest programmeerimisest. Peamine eripära on see, et mudel õpib ise andmetest mustreid, võimaldades lahendada keerulisi ülesandeid, mis tavapärase programmeerimisega oleksid peaaegu võimatud.